
机器之心报道
机器之心编辑部
最近,一个对标 GPT-4o 的开源实时语音多模态模型火了。
这个开源模型来自法国一个仅有 8 人的非营利性 AI 研究机构 ——Kyutai,模型名为 Moshi,具备听、说、看的多模态功能。图灵奖得主 Yann LeCun 转发说道:「Moshi 能听懂带有法国口音的英语。」据悉,该团队开发这个模型仅用了 6 个月。
的确,在研究团队演示的视频中,我们发现 Moshi 可以非常流利地回答人们提出的问题,进行日常对话交流,甚至可以猜出提问者的意图。
例如,当提问者说「下个月打算去攀登珠穆朗玛峰,我在想......」,提问者话说到一半,Moshi 就说道:「太了不起了,你需要带些什么装备呢」,提问者则表示:「这正是我想讨论的话题,你觉得我需要带些什么呢」。于是,Moshi 给出了一些攀登设备的专业建议,并回答了关于注意事项的问题:
我们发现 Moshi 还会开些小玩笑:「你肯定不想穿着凉鞋去爬山」。
研究团队还用各种说话风格展示了 Moshi 表达和理解情绪的能力。例如,让 Moshi 用法国口音诵读诗句:
不过这首诗太长了,研究人员打断了 Moshi 的朗诵,Moshi 立即停了下来。
作为一个多模态大模型,Moshi 的角色扮演能力也是很强的,以海盗身份讲述海上冒险故事,那也是张口就来:
当提问者问道海盗船叫什么名字,Moshi 还反客为主,反问提问者:「你叫什么名字,是什么让你过上了海盗生活?」不得不说,提问者此时显得有些被动了。
最后,研究人员还让 Moshi 用低声细语讲一个神秘的故事:
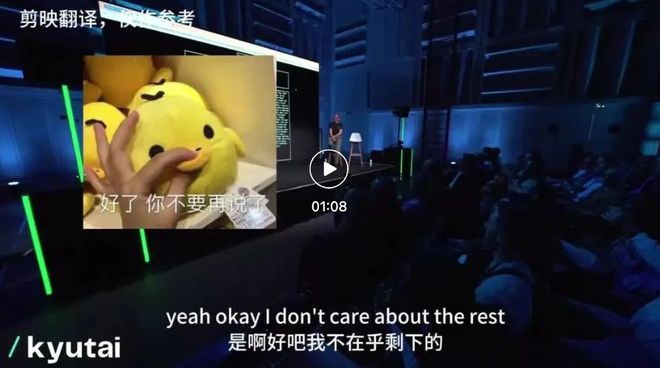
不过,Moshi 讲的有些陶醉,研究人员多次打断未果。最后还是研究人员压低声音,用跟 Moshi 类似的语气提出下一个问题,才让 Moshi 继续回答了下一个问题,这大概就是用魔法打败魔法吧。继续回答问题时,研究人员表示对一些细节没有兴趣,Moshi 还是自顾自地继续讲,直到在大家的掌声中,它才真的停止。
Moshi 的背后:合成数据立大功
Moshi 的设计目的是理解和表达情感,具有诸如用不同口音(包括法语)说话的能力。它可以聆听和生成音频和语音,同时保持文本思维的无缝流动。Moshi 的一个突出特点是能够同时处理两个音频流,使其可以同时聆听和说话。这种实时交互基于文本和音频混合的联合预训练,利用来自 Helium 的合成文本数据,这是一个由 Kyutai 开发的 70 亿参数语言模型。
Moshi 的微调过程涉及使用文本到语音 (TTS) 技术转换的 100,000 个「口语风格」的合成对话。模型的语音在一个单独的 TTS 模型生成的合成数据上进行训练,实现了令人印象深刻的 200 毫秒端到端延迟。值得注意的是,Kyutai 还开发了一个可以在 MacBook 或消费级 GPU 上运行的 Moshi 小型版本,使其可以被更广泛的群体使用。
Moshi 的核心是一个处理语音输入和输出的 70 亿参数多模态语言模型。该模型采用双通道输入 / 输出系统,同时生成文本 token 和音频编解码器。基础文本语言模型 Helium 7B 从零开始训练,然后与文本和音频编解码器联合训练。语音编解码器基于 Kyutai 内部的 Mimi 模型,具有 300 倍的压缩系数,可捕捉语义和声音信息。
训练 Moshi 涉及严格的过程,微调了 100,000 个高度详细的带有情感和风格注释的转录结果。文本转语音引擎支持 70 种不同的情绪和风格,是根据一位名叫 Alice 的有**的声音达人录制的 20 个小时的音频进行微调的。该模型具有适应性,可以在不到 30 分钟的音频中进行微调。
Moshi 的部署展示了其效率。演示模型托管在 Scaleway 和 hug Face 平台上,可以在 24 GB 的 VRAM 上处理两个 batch size。它支持各种后端,包括 CUDA、Metal 和 CPU,并受益于 Rust 对推理代码的优化。增强的 KV 缓存和**缓存有望进一步提高性能。
展望未来,Kyutai 对 Moshi 有雄心勃勃的计划。团队计划发布技术报告和开放模型版本,包括推理代码库、7B 模型、音频编解码器和完整的优化堆栈。未来版本如 Moshi 1.1、1.2 和 2.0 将根据用户反馈改进模型。Moshi 的许可旨在尽可能宽松,促进广泛采用和创新。
总之,Moshi 体现了小型专注团队在 AI 技术方面取得非凡进展的潜力。这个模型为研究辅助、头脑风暴、语言学习等开辟了新途径,展示了 AI 在端侧部署时的变革力量。
LeCun 坐镇,三十年 AI 老兵带队,
这是一支小而精的欧洲团队
Kyutai 是欧洲首个致力于人工智能开放研究的私人倡议实验室,由 iliad 集团、CMA CGM 集团和 Schmidt Futures 于 2023 年 11 月共同创立,初始资金近 3 亿欧元。
Kyutai 定位为人工智能开放科学实验室,是一个非营利组织,其使命是解决现代人工智能的基本挑战。Kyutai 专注于开发包含文本、声音、图像等的大型多模态模型,旨在发明新的算法来增强这些模型的能力、可靠性和效率。借助 iliad 集团子公司 Scaleway 提供的计算能力,Kyutai 将欧洲最高性能的超级计算机用于人工智能应用。
该实验室坚决致力于人工智能的民主化,并将自己定位为人工智能开放科学的领导者。Kyutai 的野心不仅限于科学进步,还旨在与全球人工智能生态系统分享其进展。
Kyutai 组建了一支由具有杰出学术和商业背景的优秀研究人员组成的团队,在巴黎设有办事处。其创始团队包括:
首席执行官 Patrick Pérez:在计算机视觉和机器学习领域拥有三十多年经验的专业人士;
首席扩展(scaling)官 Edouard Grave:在大语言模型和自然语言处理方面拥有专业知识;
首席科学官 Hervé Jégou:因对计算机视觉和压缩域搜索算法的贡献而闻名;
首席技术官 Laurent Mazaré:在应用数学、密码学和机器学习方面经验丰富;
首席建模官 Neil Zeghidour:前 Google DeepMind 研究员,专门研究生成音频;
创始科学家 Alexandre Défossez:专门研究机器学习应用数学。

其中,前三人都是 Google Scholar 被引量高达 40000 + 的学术大牛。
CEO Patrick Pérez 硕士毕业于巴黎中央理工学院,博士在雷恩大学攻读信号处理专业。在创办 Kyutai 之前,他是法资世界 500 强企业法雷奥(valeo)公司人工智能副总裁兼 valeo.ai 的科学总监,valeo.ai 是一个专注于法雷奥**应用尤其是自动驾驶**的人工智能研究实验室。在加入法雷奥之前,他还曾在 Technicolor (2009-2018)、Inria (1993-2000、2004-2009) 和微软剑桥研究院 (2000-2004) 担任研究员。他的研究范围包括多模态场景理解和计算成像。
首席扩展官 Edouard Grave 之前在 Facebook AI Research(FAIR)担任研究科学家。他的研究目标是设计能够理解自然语言的计算机系统。更确切地说,他的研究重点是为自然语言处理开发强大的机器学习算法,这种算法只需要最少的监督。他的工作的另一个重要方面是设计计算效率高的方法,从而将 AI 模型扩展到大规模数据集。
首席科学官 Hervé Jégou 曾在 FAIR 担任高管,研究方向是大规模索引、人工智能、机器学习及应用。他最出名的发明是「乘积量化(product quantization)」搜索,它为最流行的矢量搜索库 FAISS 和 ScanNN 提供了动力。此外,他还启动了 FAISS 库并编写了它的第一个实现。
Kyutai 的科学委员会由三名国际知名人工智能专家组成:韩国科学家 Yejin Choi,专门研究自然语言处理和计算机视觉;Yann LeCun(法国研究员、深度学习先驱、Meta 首席人工智能科学家)和 Bernhard Schölkopf(以机器学习领域的工作而闻名的德国研究员)。
iliad 集团董事长兼创始人 Xavier Niel 表示:「欧洲拥有赢得人工智能竞赛所需的一切。通过在巴黎创建人工智能开放研究实验室,我们进一步加快了步伐。Kyutai 将为我们提供超高性能、可靠的人工智能模型,整个欧洲人工智能生态系统都将能够从中受益。」
参考链接: