
团队介绍
|PROFILE
团队名称:对对对团队
名次:优胜奖
主要成员:赵其昌、赵皓晨、郭林沅、李雅洁、邓超

中南大学、五邑大学
对对对团队
“这次比赛对我来说是一个验证自己研究方向的好机会。”对对对团队队长,中南大学计算机学院在读博士生赵其昌表示,“我希望通过这个平台来测试我的模型的有效性,并检验我的思路是否适合实际应用场景。”
在大家的印象中,
可能一个生物学家的实验室是这样的

但赵其昌和他的团队办公室或许是这样

“计算生物学能够极大地减少生物或化学领域的代价问题,无论是时间上还是成本上的。”在采访中,对对对团队队长,中南大学计算机学院在读博士生赵其昌表达了对计算生物学的满满信心,一款新药从开始研发到成功上市,需要花费10多年甚至几十年的时间,需要耗费数十亿资金,不断上涨的成本却并没有换来更高的成功率。“计算生物学可以通过计算机进行初步筛选,剔除无意义的样本,然后再用生物手段进行验证,这样可以显著缩短研发时间并降低成本。”

“这次比赛对我来说是一个验证自己研究方向的好机会。”对对对团队队长,中南大学计算机学院在读博士生赵其昌表示,“我希望通过这个平台来测试我的模型的有效性,并检验我的思路是否适合实际应用场景。”
据悉,本次上海国际计算生物学创新大赛共有86支团队入围初赛,用AI算法研发的约1000个分子进入湿实验阶段。经实验检测,10个团队的12个分子进入复审阶段一环节。

“能够入围前十我们感到非常高兴。我们的运气非常好。同时,我们团队在半个月左右迅速完成了整个流程,这证明了我们的研究思路是相对正确的,这对我们后续的科研任务是一个巨大的鼓舞。证明自己并不是闭门造车,想当然的在做这样一个事情。”
据赵其昌透露,比赛中使用的模型基于他们已有的工作,目前,已经完成初稿,并已投稿至《Nature,communications》杂志,正在审稿阶段。“这是我们学术成果的一次转化。”
1
“比赛验证了团队的研究思路是相对正确的”
@上海科技
请先介绍一下您和您团队这次参赛的项目
@赵其昌
我们参加这次比赛的算法与我博士期间的研究工作紧密相关。这次的模型主要是从比赛对模型泛化能力的要求的考量出发来做的。
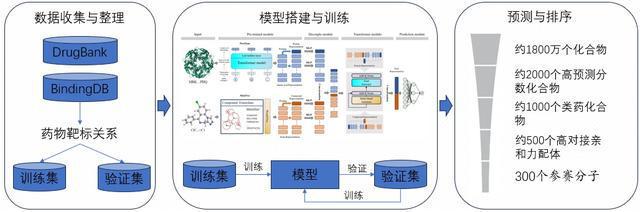
我们采用了生物学领域的大型语言模型或预训练模型来对蛋白质和小分子化合物进行特征提取。基于这些提取的特征矩阵,我们构建了一个预测模型,用于预测药物与蛋白质之间的相互作用。接着,我们利用这个模型对比赛指定的化合物库进行了全面筛选,初步缩小了候选分子的范围。
在第一步筛选后,我们进一步提取了这些化合物的三维结构,并采用对接方法对它们进行了再次排序。最后,我们根据比赛要求,从排序结果中挑选了合适数量的化合物,并将这些结果上传,完成了我们项目的整个流程。
@上海科技
您目前的研究重点是什么?这个领域在全球范围内的发展趋势是怎样的?
@赵其昌
我的科研目标专注于探究蛋白质与小分子之间的靶标关系,这与本次大赛的宗旨高度契合。在药物研发的早期阶段,药物靶标关系预测扮演着至关重要的角色,对于计算机辅助药物发现的整体流程具有显著影响。

在本次比赛中,我们采用了分类模型的方法。但其实在我们这个流程上还有一个更重要的方向叫做生成模型,也是本次大赛强调的方向。生成模型的关键在于,它不依赖于现有数据库中的化合物,而是能够创造全新的化合物作为研究对象。虽然我们目前尚未涉足这一领域,但它在科研界正逐渐成为一种趋势。
@上海科技
在比赛过程中,有没有采用一些创新的方法来提高筛选的准确性和效率?
@赵其昌
在项目中,我们主要聚焦于两个方面。首先,我们利用预训练模型来挖掘基于已有研究的蛋白质和小分子化合物的普世表达,也就是预训练特征矩阵。基于这些特征矩阵,我们构建了一个预测模型,主要是要去挖掘分子内部的绑定关系和分子间的绑定关系,这些关系在药物与靶标的生物学事实上极为关键。
此外,我们的研究还考虑了柔性拟合的假设,将蛋白质和小分子化合物的特征视为柔性的,会根据相互作用伙伴的变化而变化。
这一假设在药物靶标的实际环境中非常重要,因为在三维空间中,配体和蛋白质在结合过程中的特征是动态变化的,而非静态不变的。
我们的模型从预训练特征和生物学事实两个维度进行构建,这可能是我们项目能够取得成果的主要原因之一。虽然假设柔性特征会使建模难度增加,但它更接近生物实际,从而提高了模型的准确性。
2
“数据的收集和整理是我们遇到一个难点”
@上海科技
团队的名字叫“对对对”,当时是怎么想到这个名字的?
@赵其昌
我当时的想法是找一个既能给人留下深刻印象又具有积极寓意的名称,同时又不能够显得太过于高调。
@上海科技
在参赛过程中,有没有遇到什么困难或者挑战?
@赵其昌

在这次比赛中,我们面临了多方面的挑战和困难。首先,数据收集是一个关键且耗时的环节。我们的队员李雅洁在这一任务上投入了大量时间,因为数据的准确性对我们模型的性能至关重要。事实上,数据的有效性在某些情况下可能与模型本身同等重要,甚至更为关键。
如果数据足够精确,我们甚至不需要对整个流程进行复杂的设计,也能获得良好的预测结果。因此,数据收集和整理是我们遇到的第一个难点。我们必须对目标靶点的数据进行严格筛选,排除任何可能影响结果的不准确信息。
其次,我们的工作流程分为两个阶段:首先是利用深度学习进行初步筛选,然后是基于对接技术的精细排序。对接部分由郭林沅队员负责,这是我相对不太熟悉的领域。由于时间紧迫,对接成为了我们的另一个难点。对接过程需要大量的计算资源和时间,而我们只能快速进行,因此只能对预测出的前1000个化合物进行对接和精细排序。这可能会使我们错过一些有效的小分子,但由于时间限制,我们无法对此进行更深入的探索。
@上海科技
这次大赛的经历对您未来的研究方向有哪些启示或影响?您有哪些新的研究计划或目标?
@赵其昌
其实,我们的导师王建新教授一直鼓励我们探索和整合整个药物研发流程。他对于学生的任务分配非常讲究,希望我们能够全面掌握药物研发的各个环节。每个学生负责流程中的一个特定模块,最终我们的目标是开发出一整套完整的药物研发流程。

这样,如果药厂提供一个蛋白质靶标,就像比赛中的情况一样,我们就能够基于此研发出一系列可信且有效的小分子药物。然后将这些研究成果交给药厂,由他们进行后续的生物实验验证。这对我们来说也是非常有意义的。
最重要的,我非常感谢王建新教授的指导和支持,感谢组员赵皓晨,郭林沅,李雅洁,邓超为比赛做出的不可或缺的贡献。
本次2023上海国际计算生物学创新大赛由上海市生物**科技产业促进中心主办,**科学院上海药物研究所原创新药研究全国重点实验室、****上海市分行、华为云计算技术有限公司、临港实验室、上海人工智能研究院、东方美谷企业集团股份有限公司、上海大宁资产经营(集团)有限公司联合主办,上海生物**公共技术服务有限公司和上海市生物**产业技术服务平台具体承办,活动也得到了上海皓元生物**科技有限公司(MCE**)协办支持。
企业及专家观点不代表官方立场
作者:许织
特别声明:本文经上观新闻客户端的“上观号”入驻单位授权发布,仅代表该入驻单位观点,“上观新闻”仅为信息发布平台,如您认为发布内容侵犯您的相关权益,请联系删除!